
|
|

|
|
|
||
|
|
|
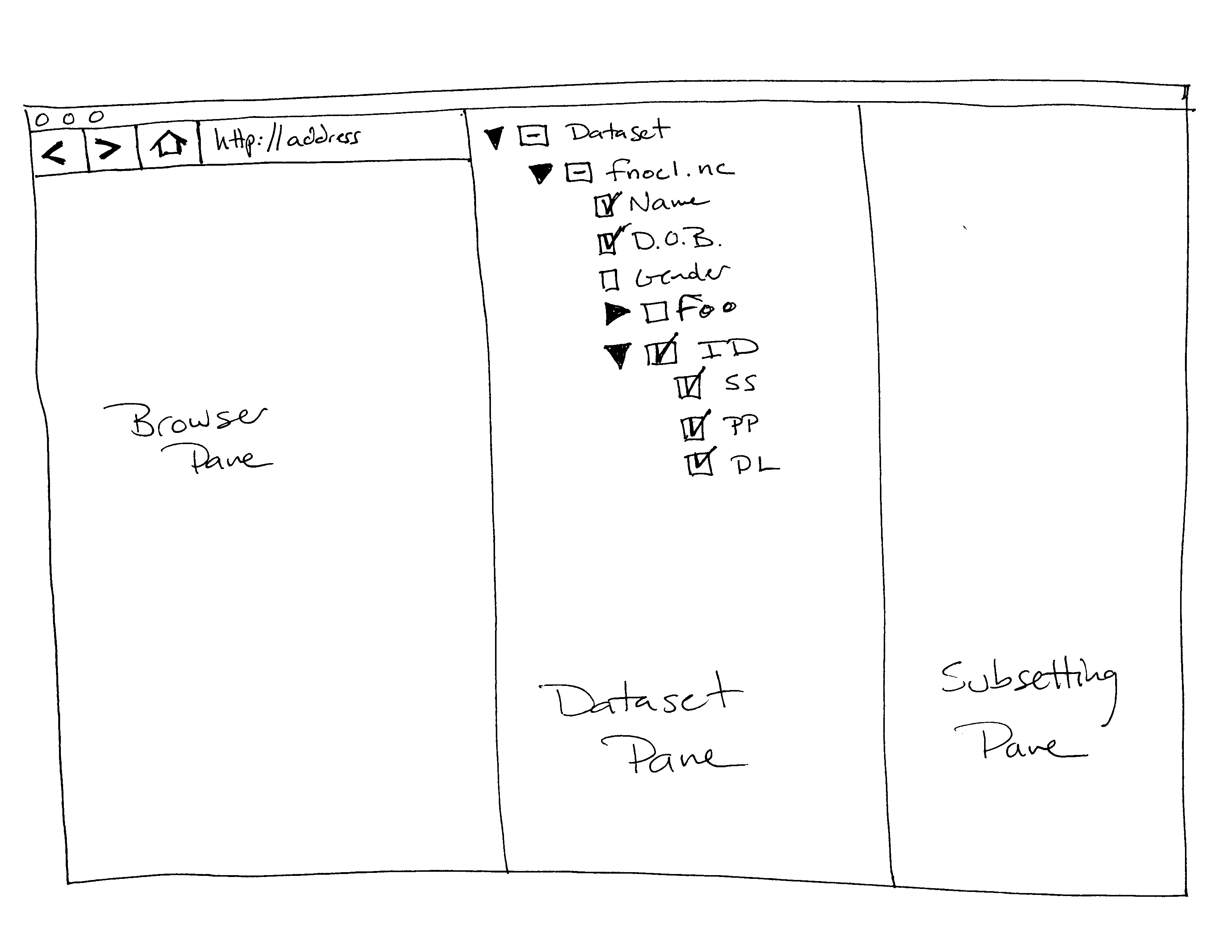
I have been prototyping a UI for getting OPeNDAP data into Kepler. My idea was to use a browser to allow the user to navigate to data sets of interest using the OPeNDAP servers web interface. When the user selects a data set by clicking on one of the DAP response types the request is caught and the DDS is rendered as a "selection" tree like one might see in a typical software installer:
Where the interface allows the user to select parts of the hierarchy by clicking the selection boxes. Selecting a node selects all of it's children. Expanding a node and selecting some of it's children causes the selection icon for the node to indicate that is partially selected (
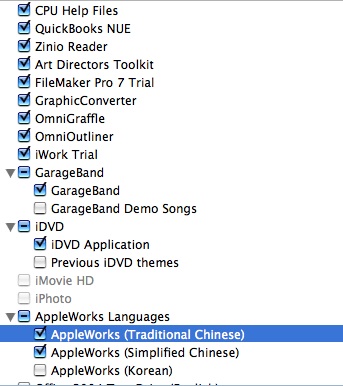
I built a simple prototype. The browser is pretty limited (it doesn't do javascript or Ajax) but it works. Here is a snapshot of the UI pointed at a collection page of the OPeNDAP test server:
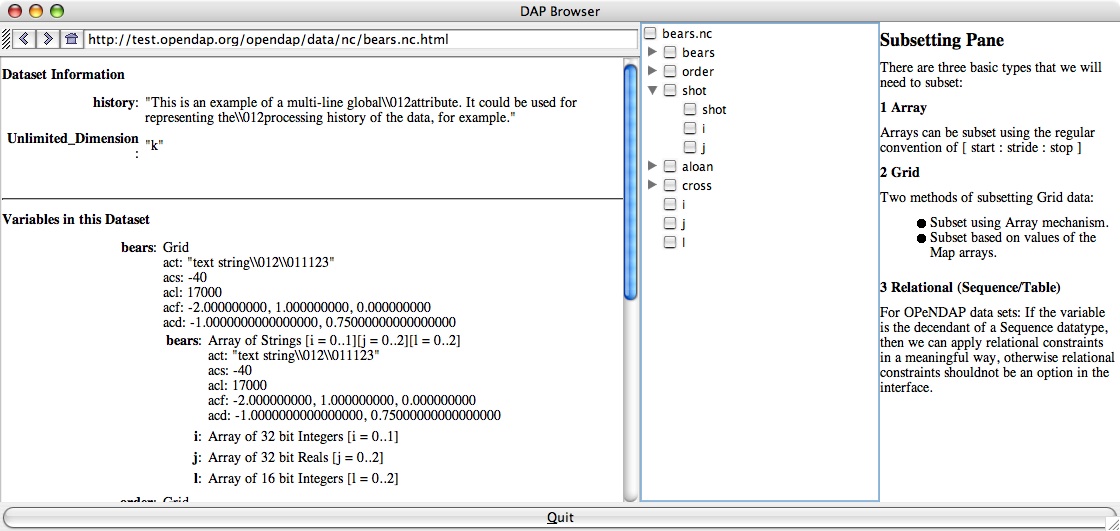
Clicking on one of the data set links on the left causes the UI to look at the dataset and load it's type hierarchy into the center pane and it's metadata into the left pane:
And I stopped writing code there because it's clearly going to get a lot more complex pretty quickly and it's time to solicit input. The rest of the idea is that when a user selects a variable by highlighting (single clicking on) the name in the data set tree the appropriate sub-setting interface appears in the Sub-setting Pane. By navigating the data set tree, clicking the check boxes, and highlighting the selected variables the user can build the data request that they want. I have some questions:
I can see a couple of things to try beyond this:
Any input you all care to give would be welcome! N James says: How about making the left panes work more like the mac's finder window. Suppose you started with a thredds catalog URL and got it's contents in the leftmost pane. Then click on an item such as a catalog and see that in the pane to the right. Suppose there were many catalogs in a nested hierarchy, the number of panes would be limited to say four, with the leftmost stuff rotating off to the left (and out of the display). Then you get to data and the thing that appears is the IFH in the pane to the right. I know that in your text on the wiki you talk about this, but I just wanted to say it too. The advantage of using the IFH is two fold: First, it can be customized and we can even install a Kepler version on a Kepler machine and use it to reference data sets/sources that are remote to it (the interface _is_ bundled with the server, but it can actually run on any machine on the network). So it's easy for us to tweak. Second, we can then direct effort to improve the IFH - a long-time goal of mine - and see benefits for all users, not just kepler users. Conversely, Kepler can also see benefits from improvements other projects make to the interface. We have not improved the interface at all since I wrote the initial version years ago (but it's widely used). I think this is largely because it's hard to update server-side code in a timely manor (although it's easier with Hyrax and we could think about/propose some innovative update techniques that are just too involved for me to get into here - I have seven minutes left before the telecon. The other reason is that I think most people want to make the 'killer app' and that's just not very often a data server...
Attachments:
|
| This material is based upon work supported by the National Science Foundation under award 0619060. Any opinions, findings and conclusions or recomendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation (NSF). Copyright 2007 |
 ). So I would sketch the UI like this:
). So I would sketch the UI like this:

 that I may be able to bend to this purpose. Lobo supports both javascript and Ajax - this is important for discovery.
that I may be able to bend to this purpose. Lobo supports both javascript and Ajax - this is important for discovery.





