|
This is version 15.
It is not the current version, and thus it cannot be edited.
[Back to current version]
[Restore this version]
The goal of the REAP SST usecase workflow (REAP-SST-UCW) is to compare and match-up existing remote-sensed (satellite) images of sea surface temperature found in OPeNDAP archives.
- User Input:
The workflow starts by getting input from the user. These inputs decide how to subset the available SST datasets.
- The datasets to use: For now, we assume only 2D fields, either satellite or model output (MODIS, HYCOM, etc.). Furthermore, all 2D fields in a given data set will be in the same geographic project; such data sets are referred to as Level 3 data sets$$. "The Level 3 mapped products are global gridded data sets with all points filled, even over land." Ref

- Timespan: Beginning and end timestamps.
- Time sampling: Percentage of the dataset times within the timespan.
- Time span delta: Maximum amount of time between a reference dataset time sample and the corresponding sample of another dataset (see Step 2.4)
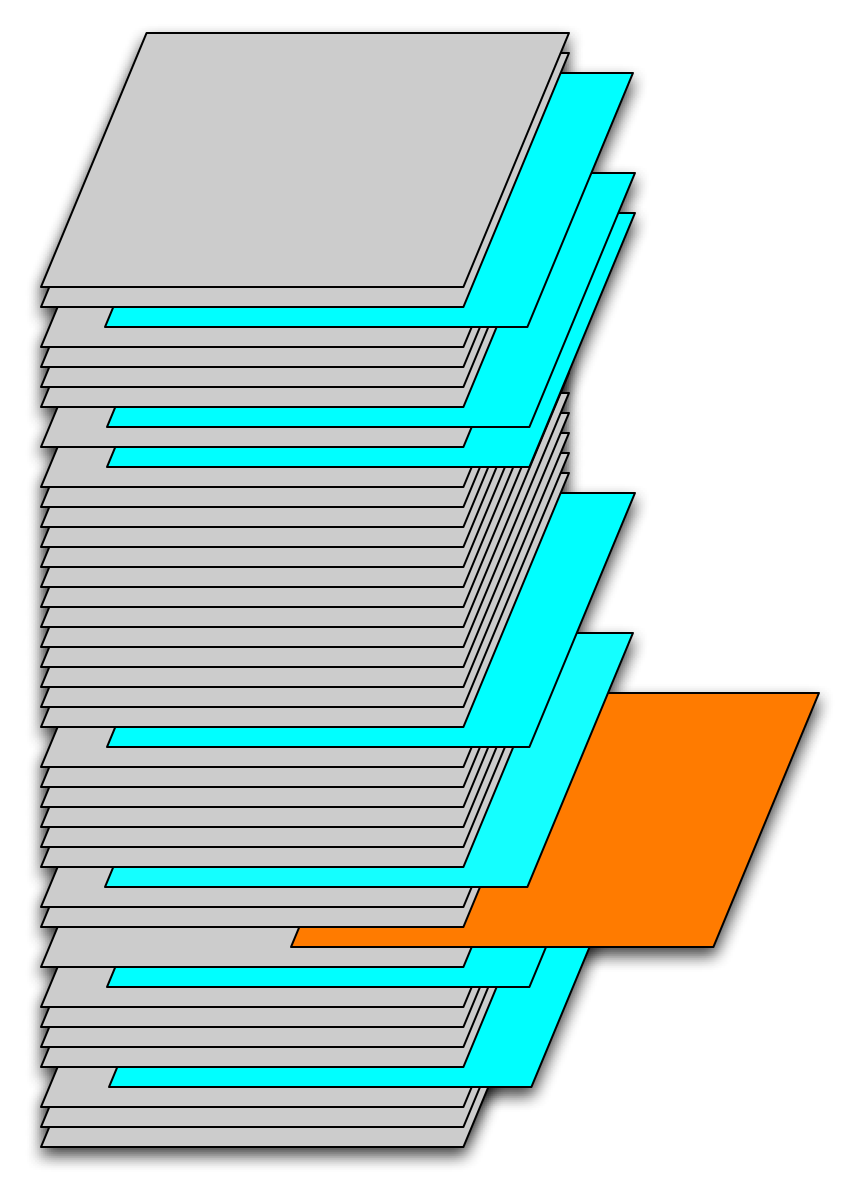
Figure 1. Temporal samples from a time series of SST fields.}
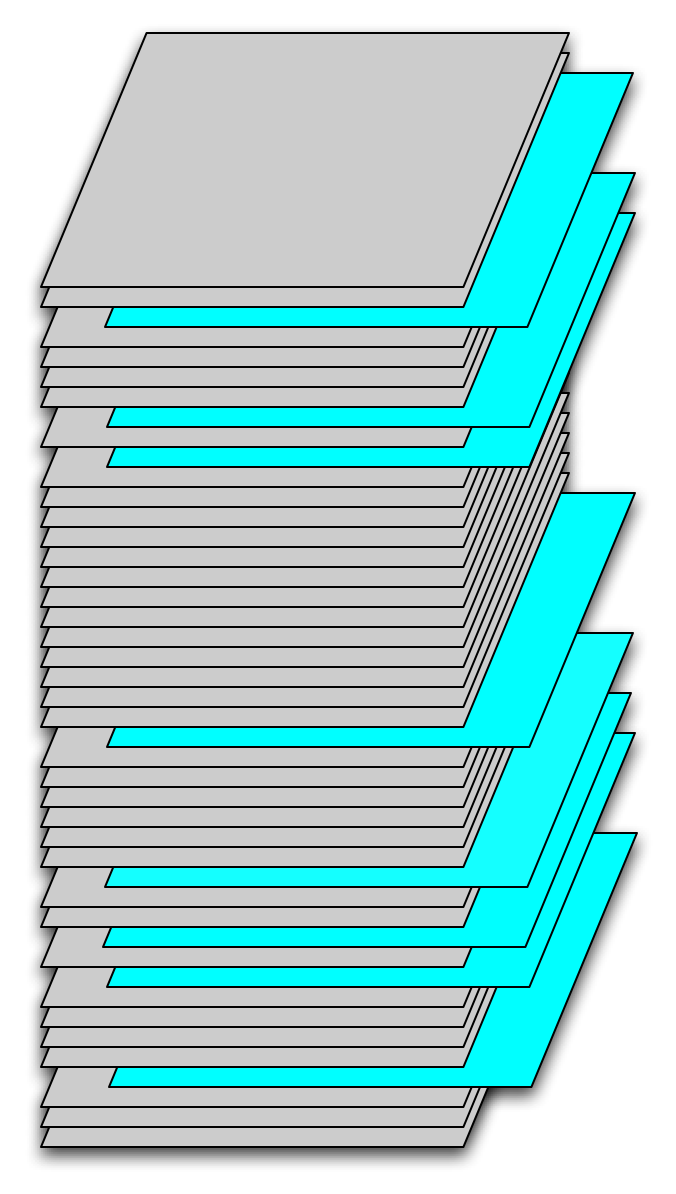 |
- Maximum and minimum latitudes: Latitude ranges for the spatial region
- Maximum and minimum longitudes: Longitude ranges for the spatial region
- Spatial sampling: Percentage of the area defined by the min/max latitudes and longitudes to sample.
We need the ppt figure from Peter C.
- Spatial window delta: Maximum amount of overlap between a reference dataset and the corresponding region of another dataset
We need the ppt figure from Peter C.
- MinNumberOfPixels:
- Sampling ?
- TileAveraging: A tile is a rectangular region that includes a set of pixels. A pixel is atomic an area and characterized by an SST value at a lat,long that represents the center of a pixel.
- Build Match-Up Datasets:
Once the user has input parameters in step 1, the workflow builds a set of tiles or match-ups. The match-up building starts with finding the coarsest granularity of timesteps depending on the metadata for the datasets. The dataset is sampled and closest timeframe of the other datasets is determined based on this coarsest dataset.
For each timestep, the workflow finds the dataset with coarsest spatial granularity. Then the workflow randomly chooses spatial samples or tiles of this reference dataset. These are bounded by the min. and max. latitudes and longitudes. The spatial samples are randomly selected such that they cover the spatial percentage of the reference dataset.
For each spatial sample selected in the previous step, the workflow determines the corresponding sample area in each of the other datasets. The SST values for the spatial samples are retrieved for each dataset. A description of the samples retrieved is written to a database. For each sample, the description including latitude,longitude center and descriptions of the sample for each dataset (Timeframe, Array of latitudes, Array of longitudes, SST values, Number of good SST values, Sum of SST values).
- Analyze Match-Up Datasets:
The selected and saved (in an RDBMS) SST match-up dataset values can then be used in statistical comparisons. To be defined in detail after the implementation of the first two steps.
Attachments:
|






{kind=link}
{kind=link}